Fine-tuning Large Language Models: Complete Optimization Guide
4.6 (444) In stock

Unlock the power of large language models with fine-tuning. Learn its importance, process, best practices, and future trends. Case studies included.
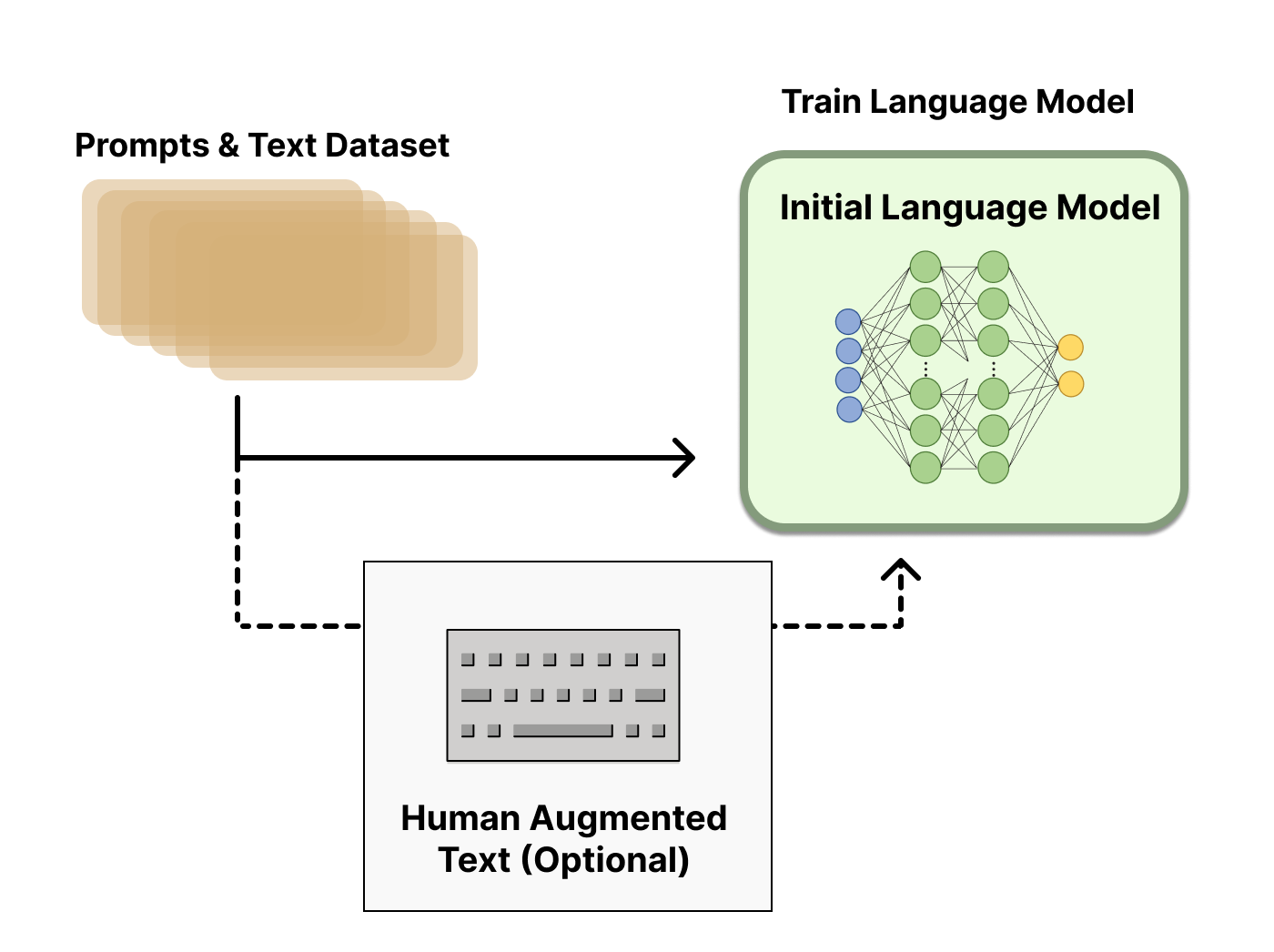
Illustrating Reinforcement Learning from Human Feedback (RLHF)

Teemu Pöyhönen on LinkedIn: RPG-GPT: Leveling up game dialogue

12. Fine-Tuning Principles for Large Language Models

Fine-tuning Large Language Models: Complete Optimization Guide
Training and fine-tuning large language models - Borealis AI
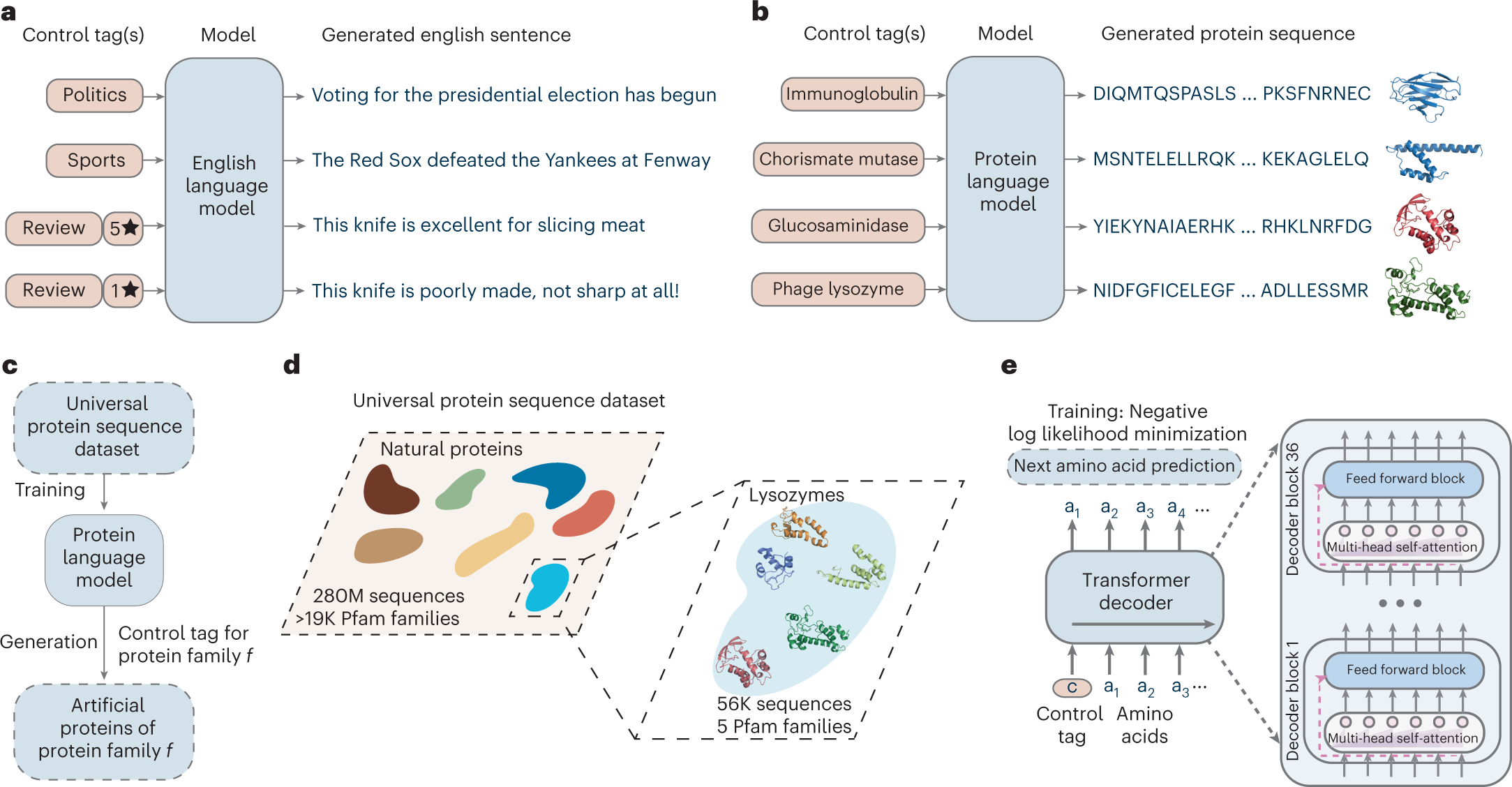
Large language models generate functional protein sequences across

A Beginner's Guide to Fine-Tuning Large Language Models

What is a Large Language Model: A Beginner's Guide
Thank You Page - Scribble Data
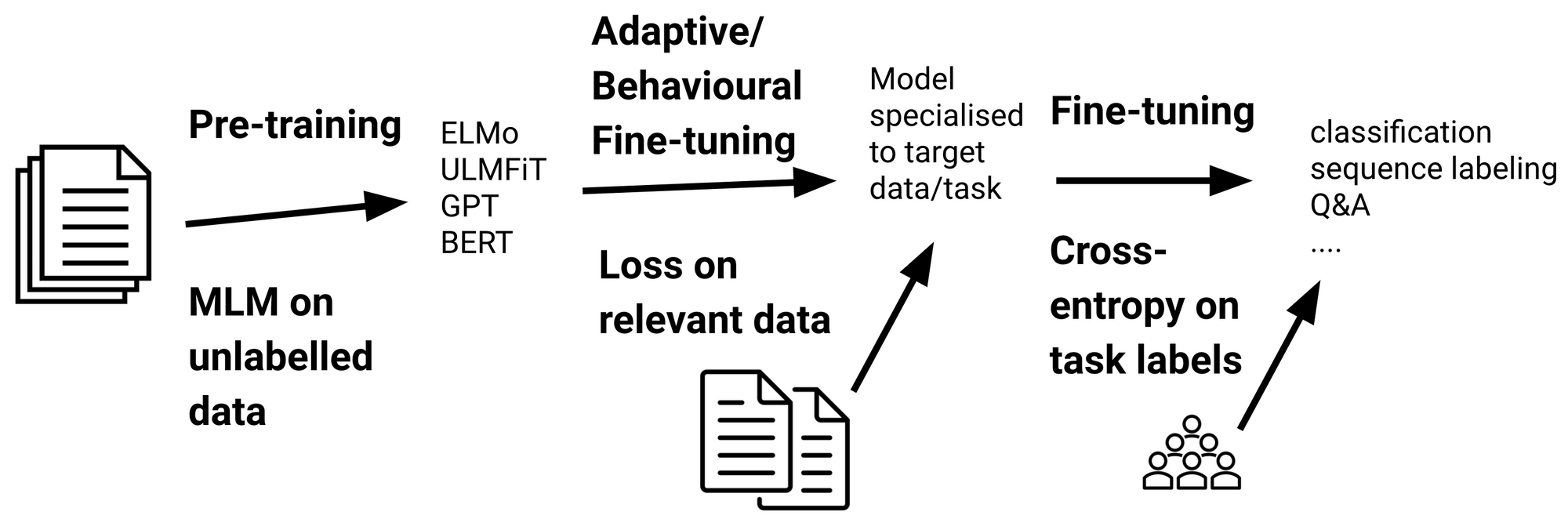
Recent Advances in Language Model Fine-tuning

LLM Optimization Parameters

LLM Optimization Parameters

LLM Optimization Parameters
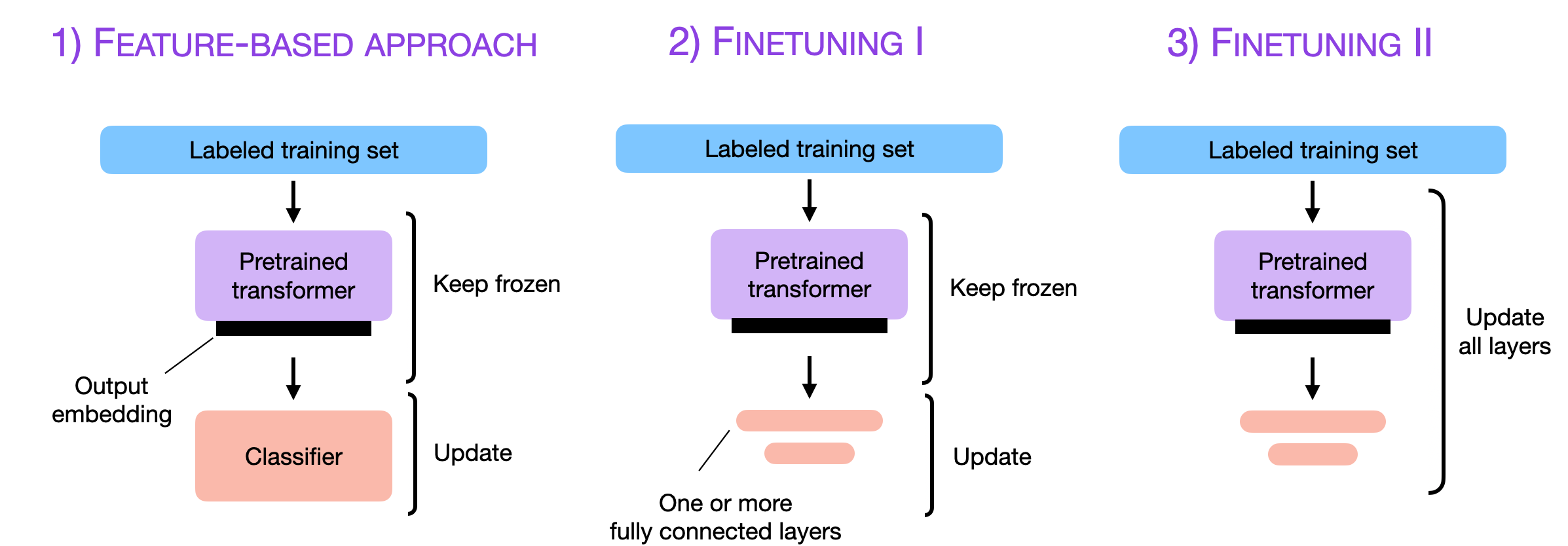
Finetuning Large Language Models
Complete Guide On Fine-Tuning LLMs using RLHF
Full Fine-Tuning, PEFT, Prompt Engineering, or RAG?
Cohere Launches Comprehensive Fine-Tuning Suite
How to fine-tune GPT-3 for your FAQ and support requests, Norah Sakal
 Ja Morant Capelli uomo nero, Stile uomo, Capelli uomo
Ja Morant Capelli uomo nero, Stile uomo, Capelli uomo:max_bytes(150000):strip_icc()/squat-alternatives-for-knee-pain-2000-f102c5a8956d42398c94b4c64ec9a29c.jpg) Squat Modifications and Tips for Knee Pain
Squat Modifications and Tips for Knee Pain Vintage Victorias Secret VSX Victoria Sport Seamless No-show Sport Hiphugger Panty Large - Canada
Vintage Victorias Secret VSX Victoria Sport Seamless No-show Sport Hiphugger Panty Large - Canada Eversocute Bra, Women Sexy Strapless Bra Invisible Push Up Bras, Wearlively Wireless Bra Support Bandeau Bra (38/85BCD, Black+Beige)
Eversocute Bra, Women Sexy Strapless Bra Invisible Push Up Bras, Wearlively Wireless Bra Support Bandeau Bra (38/85BCD, Black+Beige) Olga Bra's Set of 2 White and Purple Size 42D NWT
Olga Bra's Set of 2 White and Purple Size 42D NWT SL10618-043_02-93551d.jpg
SL10618-043_02-93551d.jpg