Language models might be able to self-correct biases—if you ask them
4.6 (612) In stock

A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.
language-models/llm-23.md at master · gopala-kr/language-models

a Knowt (@kosmo_k) / X

Anchoring Bias - The Decision Lab

Even ChatGPT Says ChatGPT Is Racially Biased

Anna Szkudlarek on LinkedIn: Language models might be able to self

Alina Polonskaia on LinkedIn: Opinion

Prompt Engineering: Talk to your Large Language Models

kmp 7+

How we can limit global warming, and GPT-4's early adopters

Language models might be able to self-correct biases—if you ask
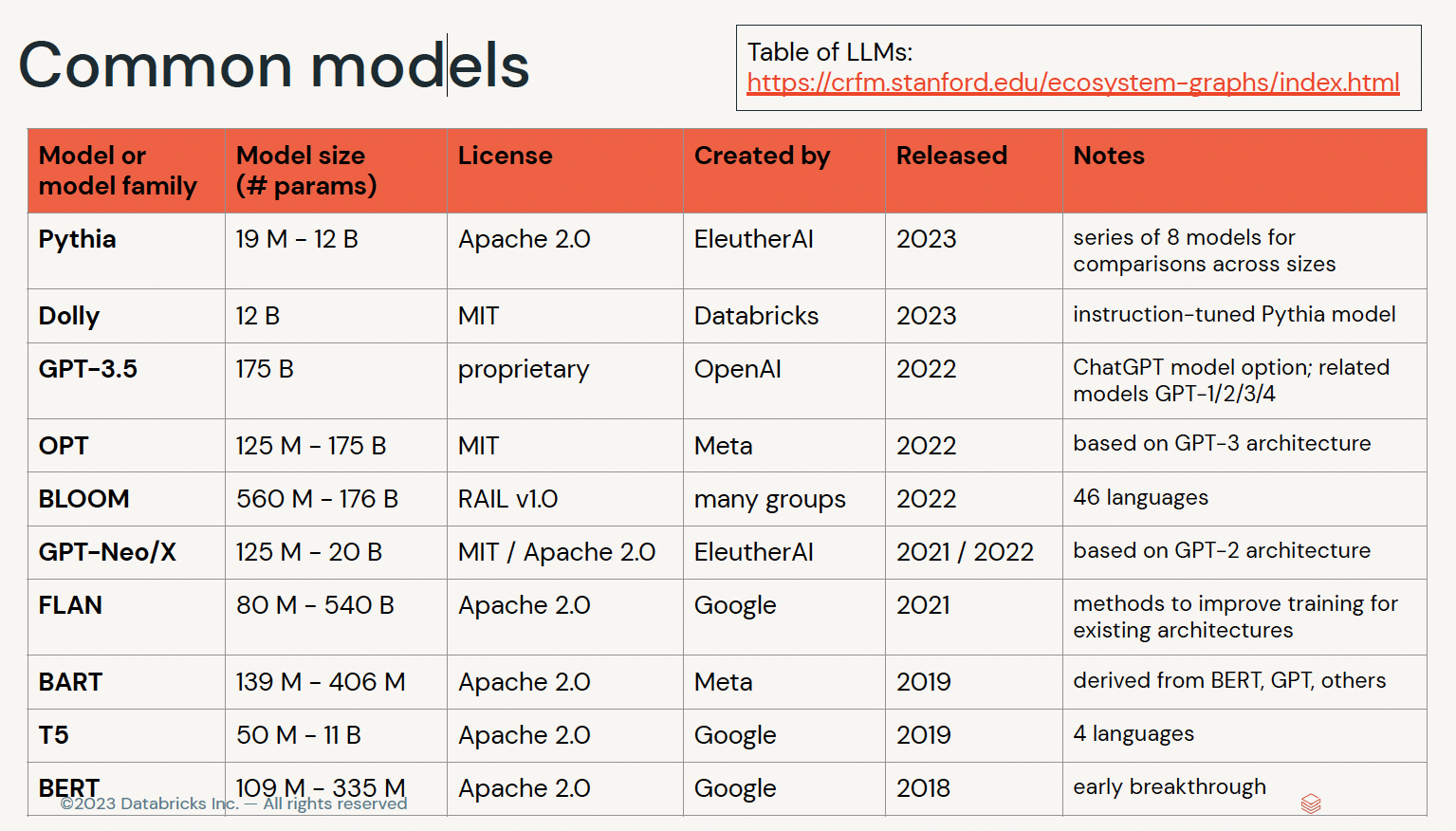
edX LLM Application through Production - ihower's Notes
Using Large Language Models With Care, by Maria Antoniak

What Is AI Bias?

AI Weekly — AI News & Leading Newsletter on Deep Learning
DNA-directed self-assembly of shape-controlled hydrogels
Mold in Crawl Space: How to Prevent and Remove It
 Women's Solid Color Yoga Clothes Long Sleeve Pants Two Piece Tight
Women's Solid Color Yoga Clothes Long Sleeve Pants Two Piece Tight You'll Poke Someone's Eye Out With Those Things: Bullet Bras From The 1940s And 1950s » Design You Trust
You'll Poke Someone's Eye Out With Those Things: Bullet Bras From The 1940s And 1950s » Design You Trust Lace Bodysuit for Women Tummy Control Full Body Shaper Deep V Neck Shapewear Bodysuit Waist Trainer Tops Backless Body Shaper (Color : 1N5359B (24V), Size : 4X-Large) : : Clothing, Shoes
Lace Bodysuit for Women Tummy Control Full Body Shaper Deep V Neck Shapewear Bodysuit Waist Trainer Tops Backless Body Shaper (Color : 1N5359B (24V), Size : 4X-Large) : : Clothing, Shoes SHEIN EZwear 4pcs Solid Ribbed Knit Bodysuit
SHEIN EZwear 4pcs Solid Ribbed Knit Bodysuit- Leonisa Firm Compression Butt-Lifting Shaper Short
 Butt Lifting Anti Cellulite Leggings For Women High Waisted Yoga Pants Workout Tummy Control Sport Tights Fitness
Butt Lifting Anti Cellulite Leggings For Women High Waisted Yoga Pants Workout Tummy Control Sport Tights Fitness
