We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
4.7 (638) In stock
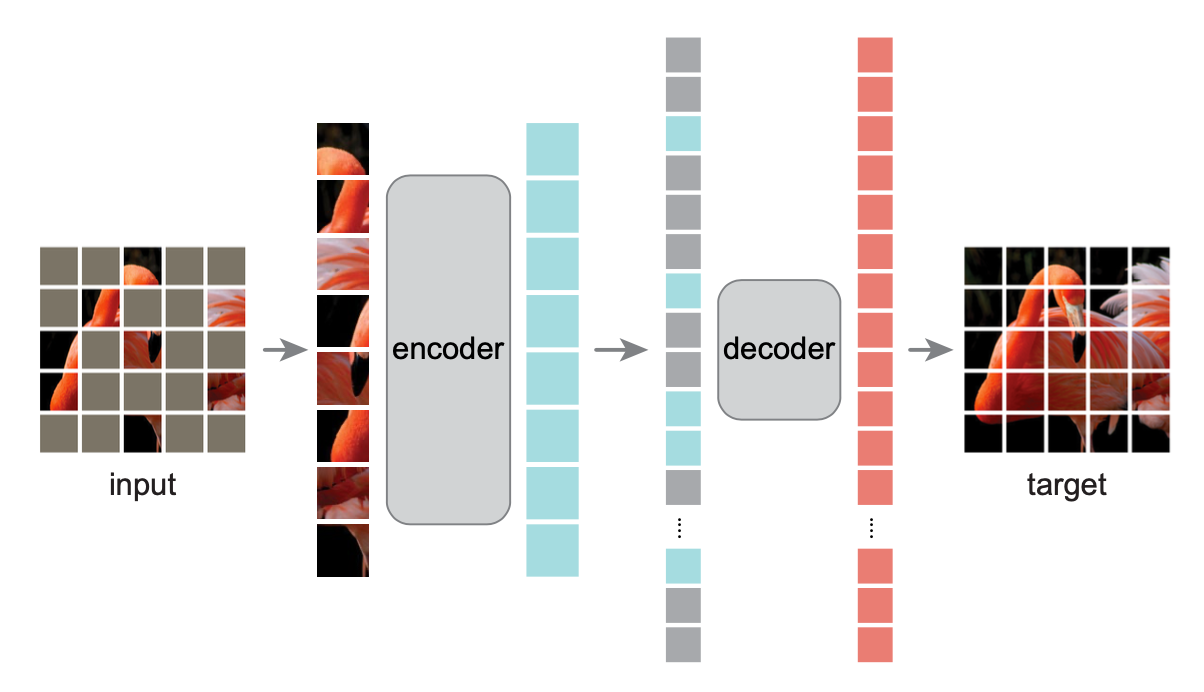
Masked Autoencoders Are Scalable Vision Learners, by Ahmed Taha

A Broad Study of Pre-training for Domain Generalization and Adaptation

PDF) How to Fine-Tune Vision Models with SGD
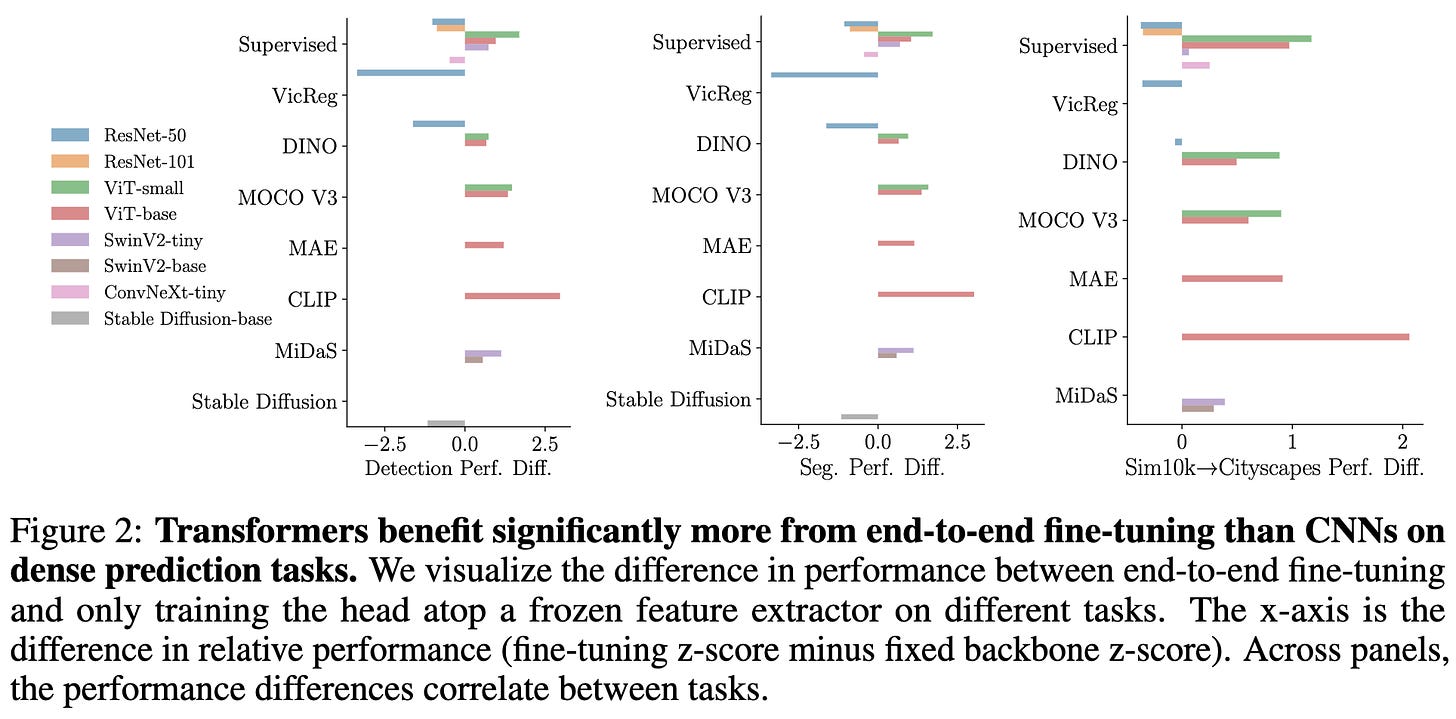
2023-11-19 arXiv roundup: Inverse-free inverse Hessians, Faster LLMs, Closed-form diffusion

D] Finetune pretrained ViT : r/MachineLearning

The freeze-out distribution, f f ree (x, p), in the rest frame of the
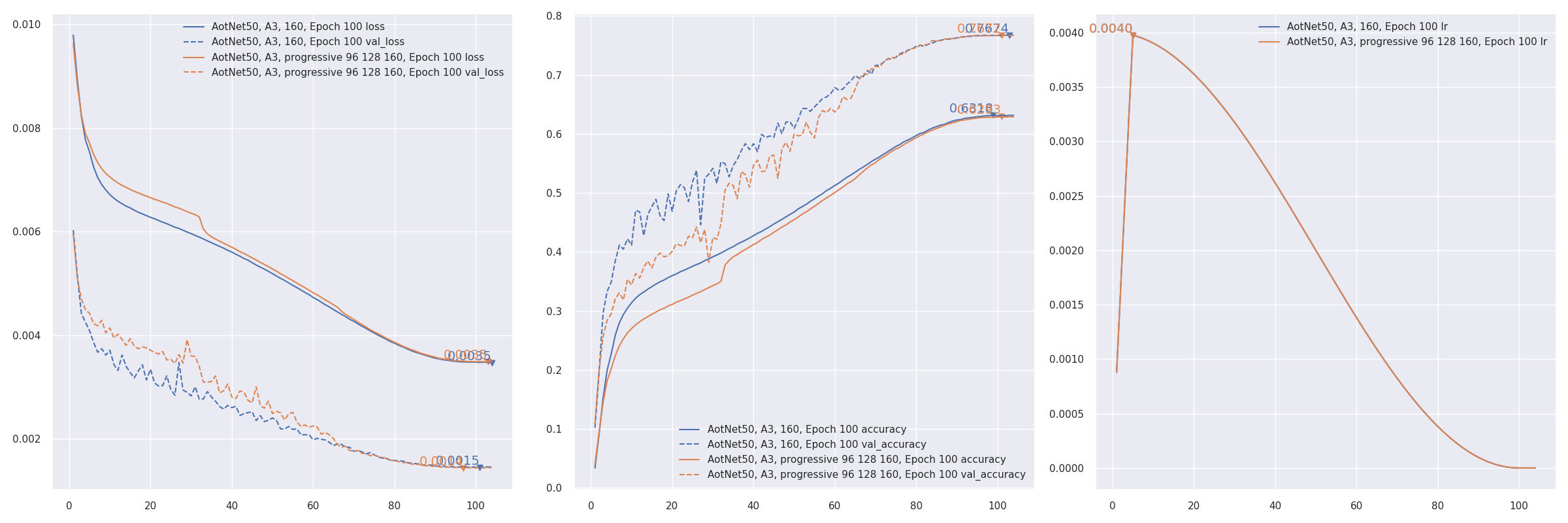
GitHub - leondgarse/keras_cv_attention_models: Keras beit,caformer,CMT,CoAtNet,convnext,davit,dino,efficientdet,edgenext,efficientformer,efficientnet,eva,fasternet,fastervit,fastvit,flexivit,gcvit,ghostnet,gpvit,hornet,hiera,iformer,inceptionnext,lcnet
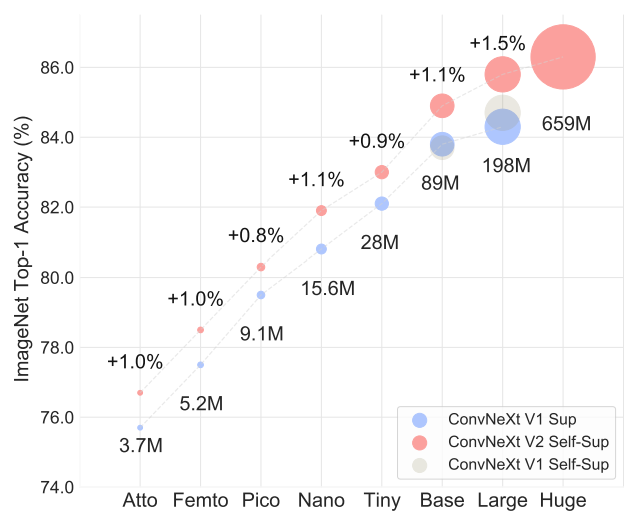
Papers Explained 94: ConvNeXt V2. The ConvNeXt model demonstrated strong…, by Ritvik Rastogi, The Deep Hub
Vision Transformer (ViT)

The freeze out distribution, f f ree (x, p), in the Rest Frame of the
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
Complete Guide On Fine-Tuning LLMs using RLHF
Fine-tuning: Unlocking the full potential of AI for businesses
How to fine-tune a GPT-3 model - All About AI
How To Fine Tune Chat-GPT (From acquiring data to using model)
- KIPSTA Thermal Tights Keepcomfort 100, Black
- 3M VALUE DUCT 1900 Scotch 1900 Duct Tape, 50m x 50mm, Black
 OQQ Women's 3 Piece Medium Support Crop Top One Shoulder Ribbed
OQQ Women's 3 Piece Medium Support Crop Top One Shoulder Ribbed Buy Boohoo Essentials High Leg Thong Bikini Brief In Green
Buy Boohoo Essentials High Leg Thong Bikini Brief In Green Super Comfortable New Ladies Plus Size Support No Steel Rings Bras Breastfeeding Sleeping Breastfeeding Bras - China Underwear and Women Underwear price
Super Comfortable New Ladies Plus Size Support No Steel Rings Bras Breastfeeding Sleeping Breastfeeding Bras - China Underwear and Women Underwear price Women Hands Free Seamless Wireless Nursing Breast Pumping Bra
Women Hands Free Seamless Wireless Nursing Breast Pumping Bra

